

 医改专题
医改专题
 医学界智库
医学界智库  2026-06-18
2026-06-18
 327
327
生成病历的医生采纳率达91%,病历书写时间缩短52%,医疗AI正迈入临床实用阶段。
撰文丨文慧
AI已成为医生的必备工具。“医学界”近期发布的调研报告显示,医生个人使用AI的比例接近九成。
但医疗大模型层出不穷,哪一款才是医生们最需要的工具?
近日,讯飞医疗推出星火医疗大模型V3.5。该模型在评测榜单上表现亮眼——不仅斩获IDC综合评测行业第一,更以98.9分登顶MedBench智能体评测,多项关键任务表现超越GPT-5.5与DeepSeek-V4-Pro。
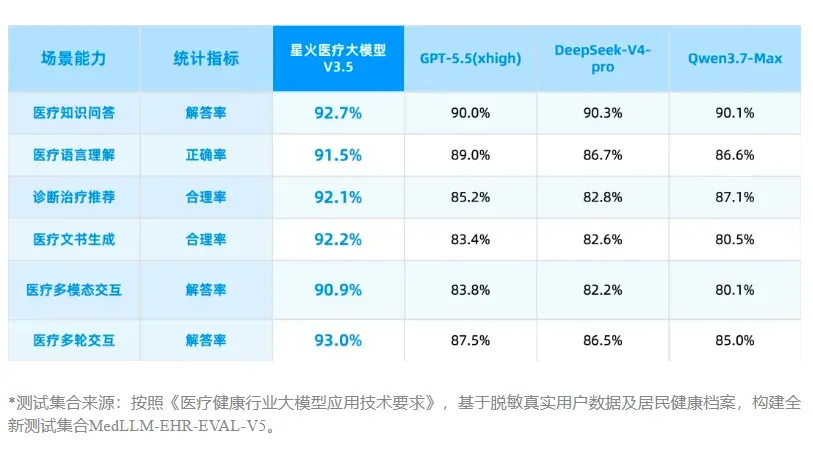
不过对临床医生而言,这些数字本身并不构成使用的直接理由。他们真正关心的问题只有一个:它能帮我解决什么实际问题?
医疗AI多项功能,首次达到实用门槛
什么工作最繁琐、最让人头疼?问遍大多数医生,答案大概率是同一个:病历等文书撰写。
按照《病历书写基本规范》,住院病历包含入院记录、病程记录、手术同意书、麻醉同意书等十几项内容,全部由医生完成。一位住院医生每天通常负责5到10位患者,光是病历书写一项,每天消耗2到3个小时并不罕见。
工作量大的同时准确性也要求高,因为病历同时是法律文书,任何差错都可能在医疗纠纷中成为不利依据。“医法汇”的统计数据显示,2023年全国医疗损害责任纠纷案件中,因病历书写不规范导致医方责任比例受影响的案件占比高达41.94%。
写错了有风险,写慢了有负担。
美国医学会(AMA)发布的《2026年医生增强智能调查》显示,文档类与摘要类工具是美国医生使用频率最高、也最感兴趣的AI应用类型。
对AI辅助病历等文书撰写表现出“极大热情”的医生比例达到57%至58%。但是,真正来使用AI做这项工作的医生尚不多,仅占28%。
热情和使用之间,是一连串实际问题,譬如语音识别不稳定,生成的病历格式不对、术语不规范,改起来比重写还费时间等。
还有更深层的隐忧,NEJM AI今年4月发表的一篇观点文章指出,AI辅助病历生成并不简单等于“减负”,医生从“自己写内容”变成“审核AI写的内容”,是两种不同性质的认知活动。
当医生开始依赖AI输出时,审核就会流于形式;而一旦遗漏高危错误,法律责任仍然落在医生头上。AI生成内容的审核负担,目前还没有得到足够认真的研究和讨论。
这篇文章提出的问题恰好表明,AI生成内容并不难,难的是生成让医生能够采纳的准确内容。
从技术演示到临床使用究竟还有多远?讯飞医疗表示,此次发布的星火医疗大模型V3.5,医疗语音识别及病历生成,在业界首次达到了实用门槛。
据讯飞医疗数据,多家头部三甲医院真实使用中,生成病历的医生采纳率达91%,病历书写时间缩短52%。
91%背后的关键突破是多源医患远场识别、多角色定向语音增强、医疗语音识别非自回归架构等多项核心技术。
诊室里同时有医生、患者、家属,声音叠加,背景嘈杂,语音识别要能区分谁在说什么、哪句话该进病历、哪句是患者的主诉。这道题极为难做。
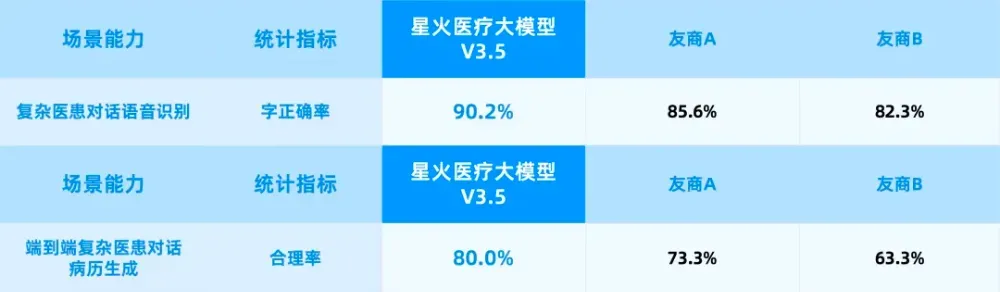
*测试集合来源:基于诊疗助理真实场景脱敏数据随机抽样。
据讯飞医疗介绍,星火医疗大模型以16亿人次脱敏医疗语音和12亿次脱敏诊疗数据为训练基础,每日持续学习超220万份真实语音、影像及病历数据,并全面升级了深度融合医疗语音识别、影像辅诊与医学语义理解的多模态能力。
如今,星火医疗大模型V3.5的端到端病历生成合理率达到80%,理论可行真正变成了临床可用。
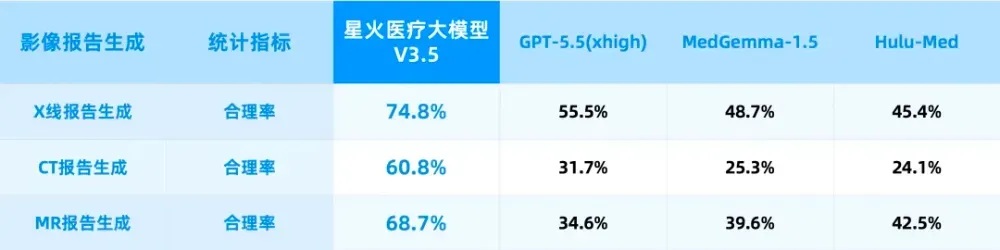
*测试集合来源:基于诊疗助理影像云真实脱敏数据随机抽样。
与此同时,影像报告生成功能也在此次升级中率先突破了实用门槛:X线和MR报告生成的医生采纳率达75%。
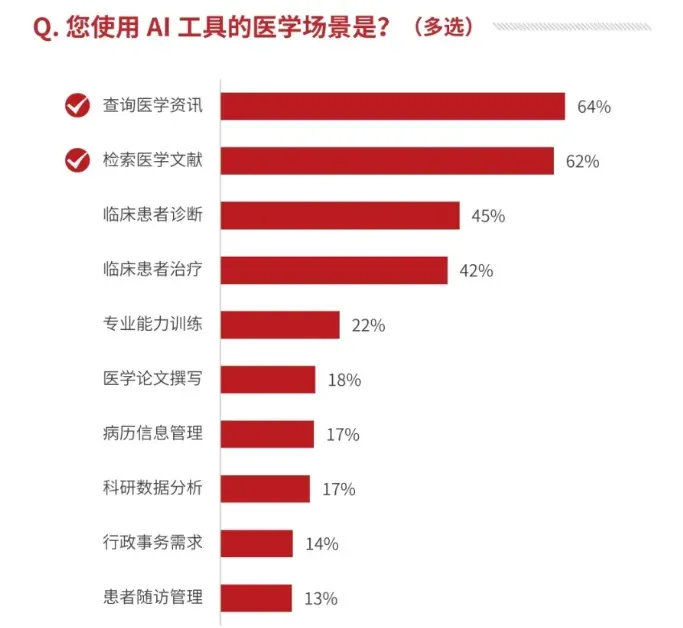
查询和检索是中国医生最常用的AI功能。图源:《医学AI大模型应用医生认知调研报告》
美国医生最希望利用AI减少文书工作,中国医生使用AI最多的场景则是医学信息的检索和查询。
“医学界”的调研数据显示,大量医生在借助AI进行资料查询与证据检索,而数据来源的可靠性是医生选择医学AI大模型的首要考量因素,选择这一选项的比例高达78%。
用AI,却又对AI给出的答案并不完全放心。这种不放心有充分的现实依据。通用AI的“幻觉”问题在医疗场景里代价极高,一条虚构的文献引用、一个凭空生成的用药剂量,在其他领域可能只是尴尬,在临床决策里可能是事故。
不少医生有过类似经历:让AI提供文献DOI,点开发现是完全不相关的文章;生成的治疗方案听起来有模有样,细查之下根本找不到出处。
星火医疗大模型V3.5的循证诊疗助理智能体,正在试图解决这个问题。它整合了中英文权威诊疗指南和医学文献,在循证长思维链技术加持下,可实现多步推理、深度反思、完整证据溯源的临床决策支持。
真实医疗数据,助力登顶
此次升级发布,讯飞医疗披露了一组数据。
据IDC《中国医疗大模型技术评估,2026》权威测评,讯飞星火医疗大模型综合实力位列行业榜首。
该测评涵盖15项核心指标,在辅助诊断、病历生成、健康咨询、诊后管理及随访等12项能力上,星火医疗大模型均获第一;测试结果表明该模型在产品落地性、安全性、规模化应用能力上表现最优。
在6月8日上海人工智能实验室开展的MedBench智能体评测中,星火医疗大模型再度登顶,综合得分98.9分。其在医疗场景感知与交互、医疗多智能体协作、医疗安全伦理与合规等多项核心能力上均位居第一。
讯飞医疗为何能做到这一点?答案不仅在于技术创新,还源于高质量的医疗数据支撑。
在算法创新方面,星火医疗大模型V3.5基于医疗高质量数据和医生交互反馈弱监督数据,实现了复杂任务“证据对齐一反思校验一专家强化”循证推理技术,显著提升医疗大模型的准确性。
支撑其的数据底座则来源于16亿人次脱敏医疗语音数据、12亿次真实诊疗数据,以及每日新增超220万份真实医疗数据的持续输入。
这离不开讯飞医疗十多年来构建的完整服务生态。基层端,覆盖全国806个区县、7.7万余家基层医疗机构;区域医疗端,影像云、数智家医椰晓医等标杆项目落地多地;医院端,携手600余家等级医院,其中涵盖50余家中国百强医院、7家十强医院;居民端,讯飞晓医APP累计下载量突破3000万。
AI模型见过的真实临床场景越多、数据越贴近真实诊疗,模型的表现才越接近临床实际需要。通用互联网数据训练出来的模型,在医疗场景里能做到的是有限的。
正如讯飞医疗总裁陶晓东博士所言:“大模型本身不是最终产品,市场看中的是其背后能解决实际问题的应用价值。仅凭技术能力不一定能做出真正有用的产品,只有对医疗行业有深刻理解,才能发现真正有价值的细分领域痛点,并将其转化成一个用户有所感知的工具。”
值得注意的是,星火医疗大模型V3.5基于全国产算力训练。在当前的信创环境下,无疑更为安全、合规。此外,该模型在国产算力平台上实现了DSA(动态稀疏注意力)与MTP(多Token预测)的长文本高效训练,实现医疗长上下文场景推理吞吐量提升4.5倍,为医院和区域医疗本地化模型部署及高效迭代提供了强大的底层技术支撑。
医疗AI发展至今,争论早已不再是“医生要不要用AI”,而是“什么样的AI值得医生用”。陶晓东也曾坦言:“医疗大模型需要回归医学本质,解决临床问题。”
从91%的病历采纳率到双榜单登顶,星火医疗大模型V3.5给出了一个方向:医疗AI的竞争力,终究要落到临床价值上来。使用者才是真正的裁判,只有切中真实痛点、经过海量临床数据打磨、安全合规的产品,才能成为医生愿意日常使用的工具。
 医改专题
医学界智库 2026-06-18
327
医改专题
医学界智库 2026-06-18
327
 医改专题
中国医药报 2026-06-17
485
医改专题
中国医药报 2026-06-17
485
 医改专题
中国医疗保险 2026-06-16
469
医改专题
中国医疗保险 2026-06-16
469
 热门资讯
热门资讯 微信公众号
微信公众号